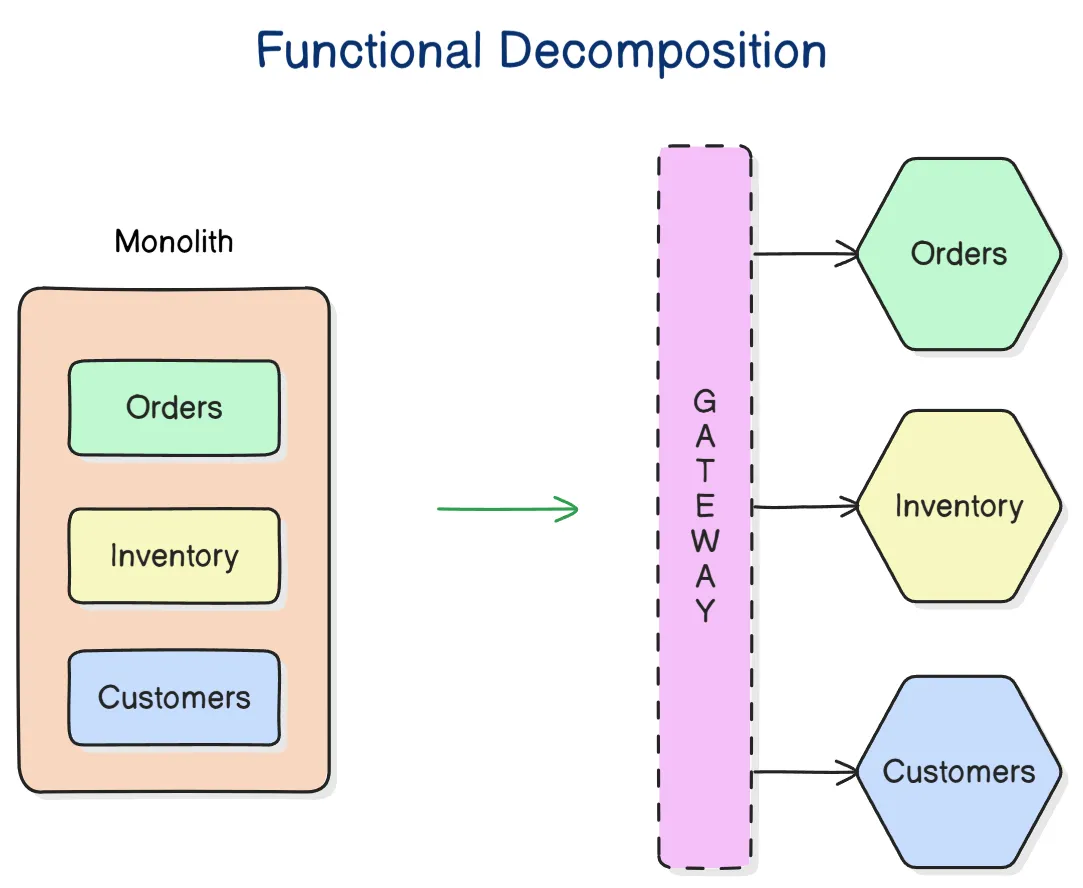
Monolith (aka. monolithic architecture)
There is no definitive definition of what is a software monolith, but generally the term is used to refer to any software system in which all the code is maintained in one [repository] and the whole application runs in a single process (though it is not necessarily a single-node application).
Before we had distributed software, all software applications were developed as monoliths.
Still today, monoliths are a great way to start building out new software systems from scratch. Starting with a monolith means you can prototype, build, test, and ship new software products quickly. Monoliths also have some performance benefits. For example, latency is low, because all the code runs in the same process.
However, monoliths get harder to develop, deploy, and operate as time goes on. You cannot easily scale up the teams who maintain monolithic systems. Monoliths are risky to deploy updates to because every change, no matter how small, requires the whole system to be redeployed. And it tends to be expensive to scale the infrastructure on which monoliths run, because you can’t target extra resources at the specific parts of the system that need them.
In summary: monoliths do not scale well.
Monoliths also tend to have lower fault tolerance than distributed software. If one part of a monolith fails, the whole system tend to go down, because it all runs in the same process.
For these reasons, modern software-as-a-service products tend to be built as distributed software, commonly designed around variations of service-oriented architecture.
Modular monoliths are a halfway point between monoliths and distributed software. They offer a mix of the simplicity of monoliths and the scalability of distributed software, as modules can be incrementally extracted into independent services as the system’s throughput and load grows over time.