Consistent hashing
Consistent hashing is a special kind of hashing technique that allows for efficient sharding of data across a cluster of nodes.
The main benefit of consistent hashing over other hashing techniques when partitioning data is that, when shards are added or removed to the cluster, the amount of data that will need to be moved between shards is minimized.
How it works
At a very high level, consistent hashing works by distributing data across an arbitrary number of nodes located around a hash range. Each data item is also hashed, using the same hash function, to give it a location on the same hash range. The node that is responsible for storing a data item is the nearest to it along the hash range.
Using this technique, when new nodes are added to the cluster, or when existing nodes are removed, the volume of data that will need to be moved between nodes will be minimized.
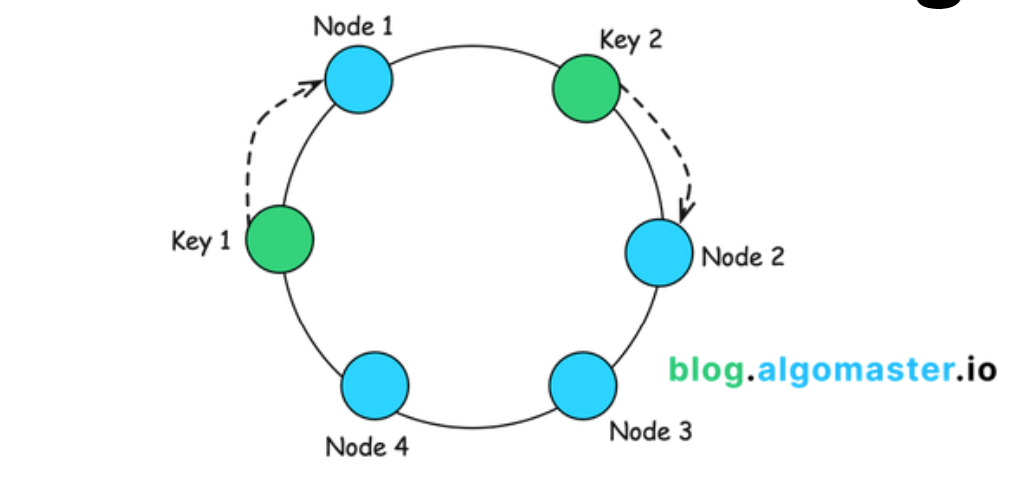
- Hash space: Imagine a fixed circular space or "ring", ranging from 0 to 2^n-1.
- Mapping servers: Each server is mapped to one or more random points within the hash space, using a hash function.
- Mapping data: Each data item is also mapped to a point within the hash space, using the same hash function.
- Data assignment: A data item is stored on the first server encountered while moving clockwise along the hash space ring from the data item’s location.